Main Contribution
- Unified Architecture(1 stage detector)
- real-time detection이 가능하도록 속도 개선
- 여러 도메인에서 object detection 가능
YOLO model output 해석
1. 이미지를 4x4 grid로 분할합니다.

2. 각 grid cell 마다 bbox(bounding box)를 2개씩 예측합니다.(여기서는 grid가 총 16개이므로 bbox는 16*2개 만큼 생성)
3. 하나의 bbox에 대해 bbox 의 중심좌표(x,y), 너비(w)와 높이(h),confidence score를 output으로 반환합니다.
(중심 좌표는 grid 셀 기준으로 0~1사이의 값을 가집니다. 예를 들어 중심좌표가 grid의 가장 왼쪽에 있을 경우 x는 0이고 가장 오른쪽에 있을 경우 x는 1이 되는 것입니다. w는 전체 사진 너비 분에 bbox너비이고 h도 마찬가지입니다.confidence score는 이 bbox가 물체를 포함한다는 예측을 얼마나 확신하는지를 의미합니다. )
4. 하나의 grid cell에 대해 conditional class probability도 반환합니다. (논문에서는 PASCAL VOC 데이터셋을 사용하였는데 class 개수는 20개였습니다. )
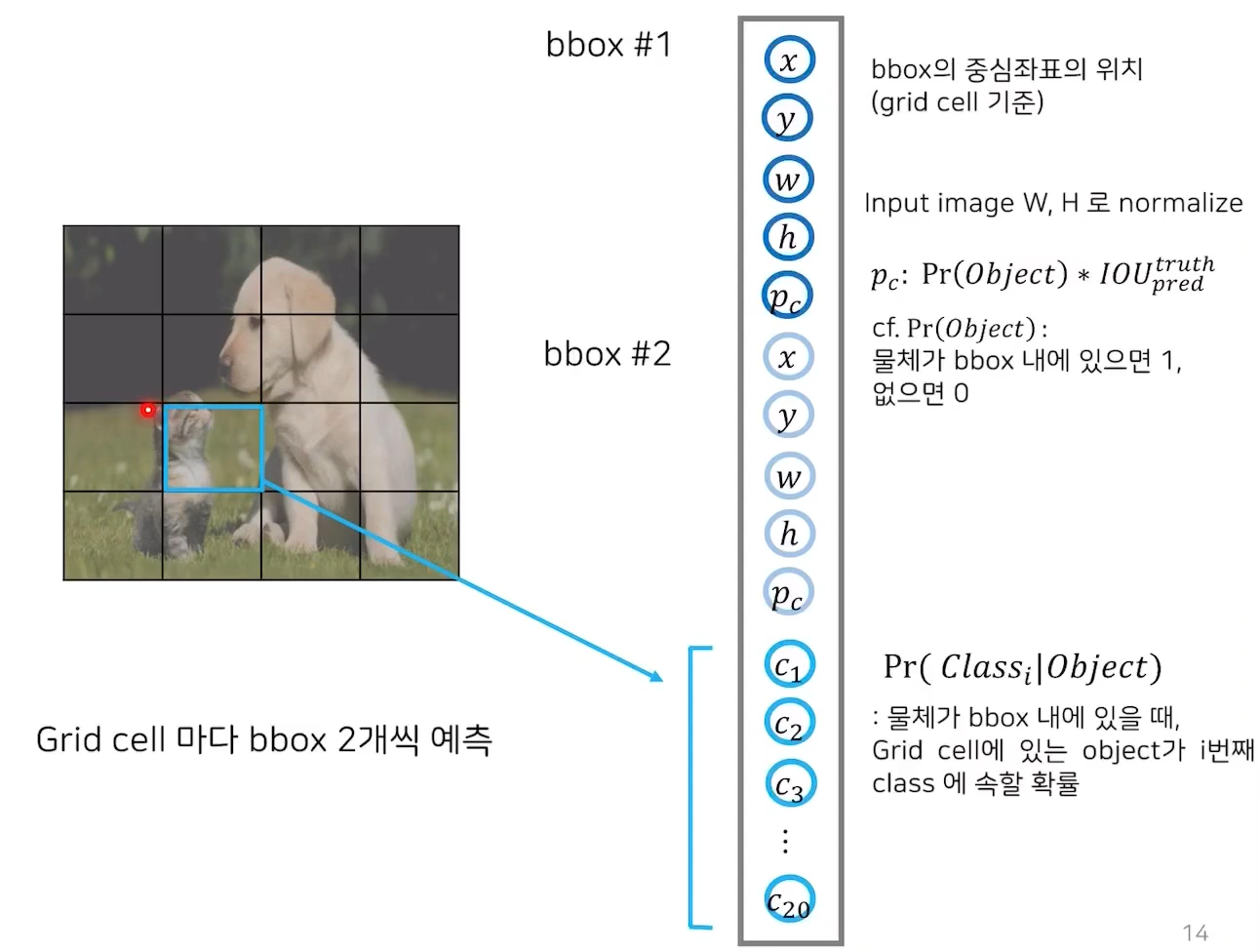
5. 하나의 grid cell에 대해 두개의 bbox와 1개의 conditional class probability를 반환하고 결론적으로 4*4*(5+5+20) tensor를 반환하게 됨
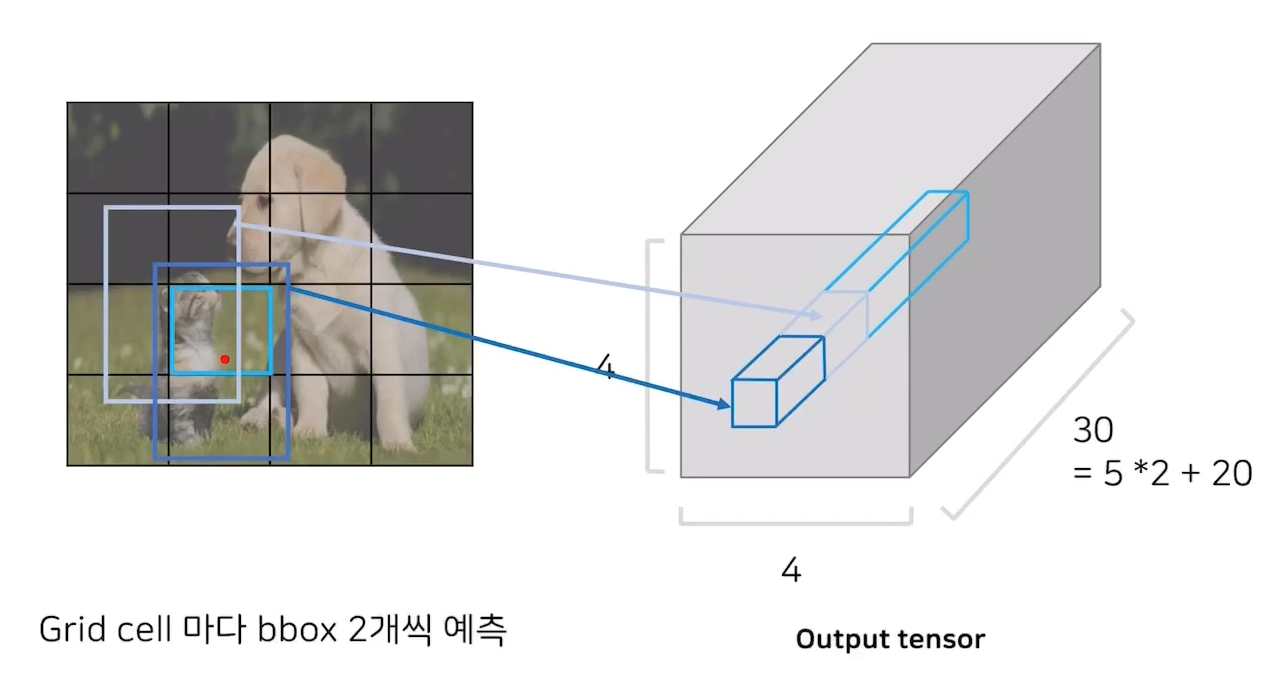
YOLO Inference 과정
Yolo 모델을 사용하면 위와같은 output tensor를 반환하게 되는데 이것을 이용해서 object detection 해보자
1. bbox 정보(위치 좌표,confidence score)와 conditional class probability를 이용해 bbox별 class probability를 구한다. 현재는 32개의 bbox가 있으므로 32개가 나올 것이다.
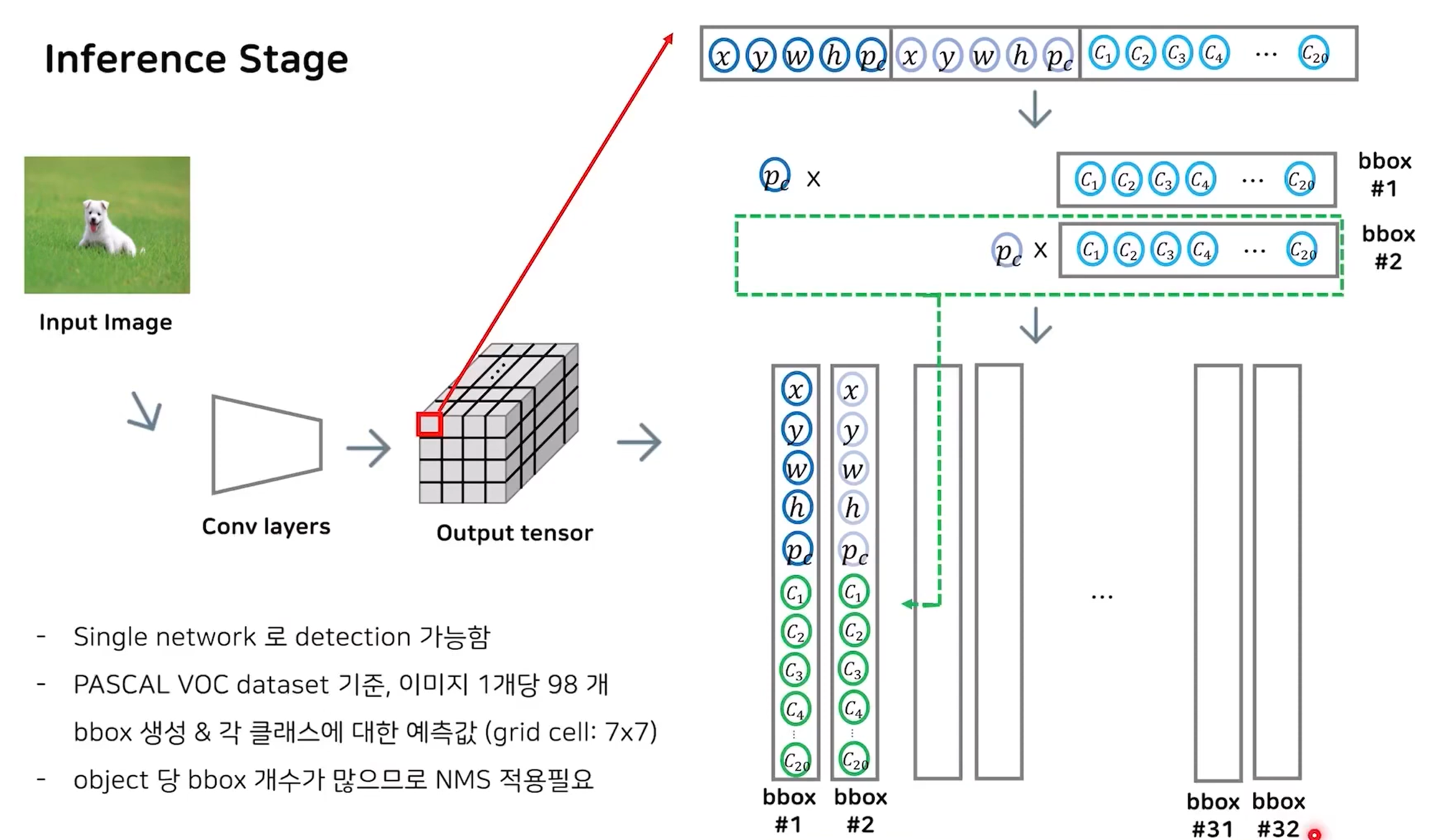
2. bbox 박스별 class probability와 위치좌표를 얻었지만 이중엔 예측력이 낮은것이 대다수 일것이다.(현재는 탐지할 object가 하나이므로 1개를 제외한 31개는 모두 제거해야 한다.)따라서 가장 예측력이 높은 것만 남기기 위해 NMS(Non-Maximum Supression)를 이용한다.
3. 클래스(개, 고양이, 사람, 책 등등) 별로 확률을 정렬을 진행한 뒤 제일 높은 확률을 가지는 것부터 Iou 계산을 통해 이 bbox가 나와 다른 물체를 탐지한 것인지 아니면 같은 것을 탐지한 것인지 알아낸다. Iou가 높으면 삭제하고 아니면 남긴다.
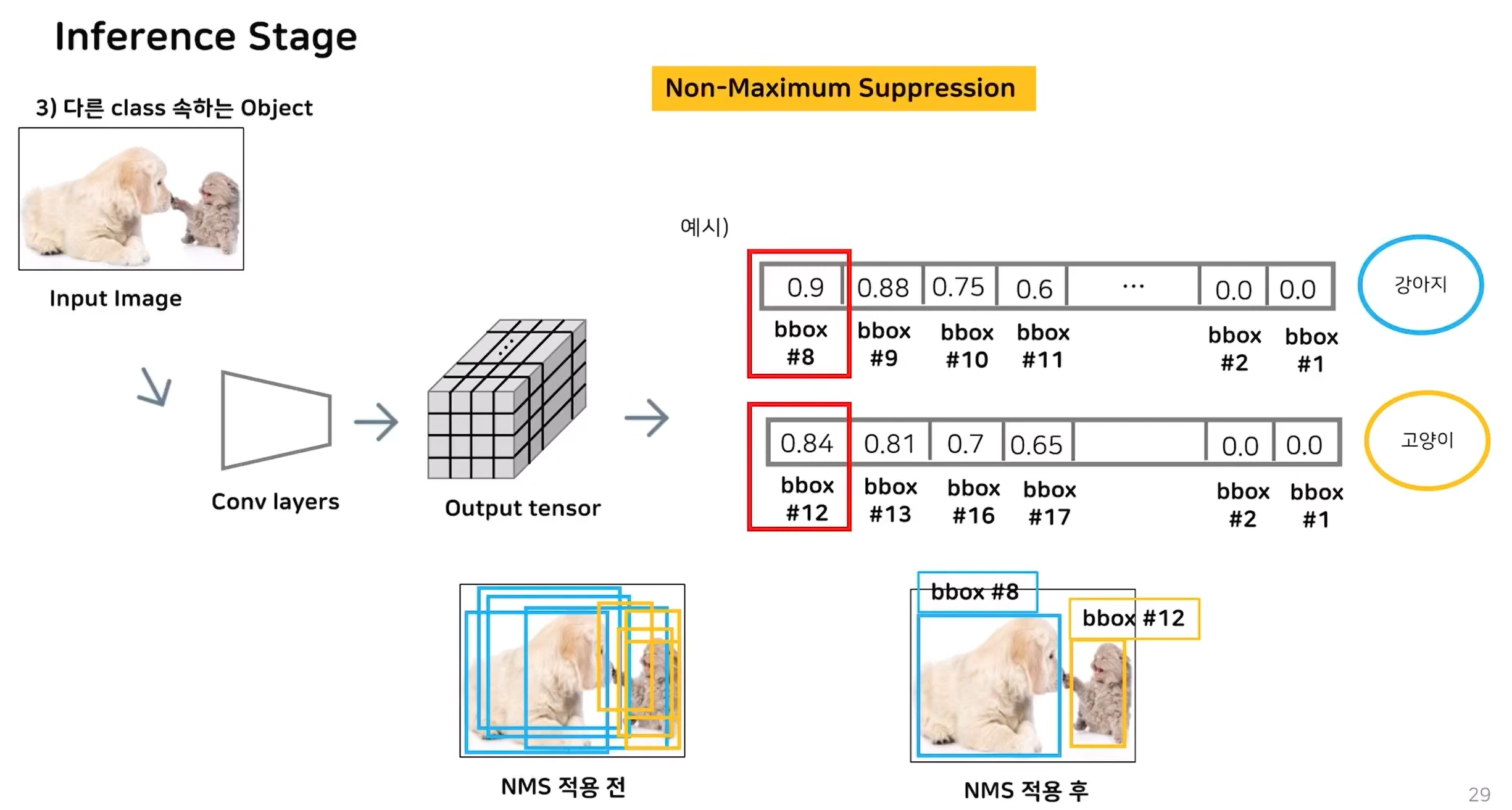
4. 클래스 별로 위와 같이 NMS를 진행하여 주면 모델이 탐지한 객체 정보를 얻을 수 있다.
YOLO training 과정
1. GT(ground truth) box를 지정하고 GT box의 중심이 위치하는 cell을 object에 responsible한 cell로 할당
2. loss function은 아래와 같다.(아직 이해를 못했다.ㅠㅠ)

Limitation
- 작은 물체에 대해서 탐지 성능 낮음
이유: object가 크면 bbox가느이 IOU값의 차이가 커져서, 적절한 predictor를 선택할 수 있지만, object가 작으면 bbox간의 IOU값의 차이가 작아서, 근소한 차이로 predictor가 결정됨
- 일반화된 지식이랑 다르게 object 비율이 달라지면 detection 성능 낮아짐
'paper review' 카테고리의 다른 글
| Learning Spatiotemporal Features with 3D Convolutional Networks (0) | 2023.09.07 |
|---|---|
| Fatigue Detection on Face Image Using FaceNet Algorithm and K-Nearest Neighbor Classifier (0) | 2023.06.29 |

