Introduction
video descriptor 의 특성 : generic, compact, efficient, simple
Contributions
1. appearance와 motion을 학습하여 feature를 추출함
2. 3x3x3 kernel 이 가장 성능이 좋음
3. compact, efficient and high accuracy
Related Work
STIPs, HOG, SIFT, iDT
Deep learning을 활용한 video feature learning
3D를 접목시키려던 시도는 계속 있었다.
HOG : Histogram of Oriented Gradient
1. Normalize gamma & color
2. Compute gradients
3. Weighted vote into spatial & orientatoin cells
: 8x8 크기의 셀로 나누고 gradient magnitude와 gradient direction을 통해 histogram에 vote => 방향에 대한 histogram을 알 수 있음

3D conv Nets 특징 & architecture
2D conv는 어떻게 하나 시간적 정보를 손실함 하지만 3D conv는 시간적 정보를 보존

architecture
공간 kernel의 크기는 3x3(k)이 2D conv에서 가장 좋았기 때문에 그대로 이용, depth 만 변경하면서 최적값(d)을 찾음
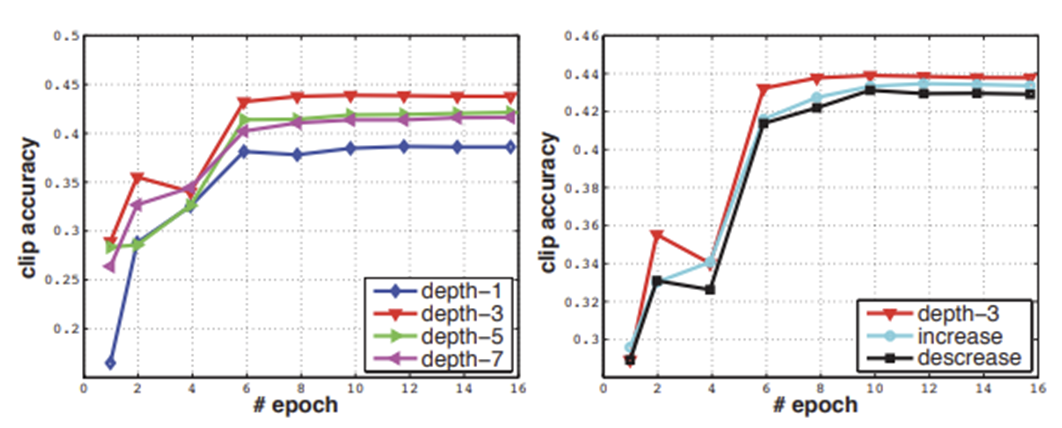
가장 좋은 kernel size: 3x3x3
Spatiotemporal feature learning
network architecture : 8 convolution layers, 5 pooling layers, two fully connected layers, softmax output layer

conv kernel : 3x3x3 (stride : 1x1x1)
pooling layers : 2x2x2 (stride : 2x2x2) / pool1 : 1x2x2 (stride : 1x2x2)
Sports-1M dataset (1.1 million sports video, 487 categories)
Sports-1M dataset training
random crop : 16x112x112
horizontally flip : 50% 확률로 flip
optimizer : SGD
batch size : 30
learning rate : 0.003
loss : softmax

deconvolution
deconvolution : top activations => image space
deconvolution을 통해 알아낸 C3D 특징 : focusing on appearance in the first few frames and tracks the salient motion in the subsequent frames
Action recognition
Action recognition : 동작들을 학습하고 이 동작이 어떤 동작인지 예측하는 task
Classification model : C3D feature extractor + linear SVM
C3D + iDT 모델의 정확도가 높음 => 서로 상호보완적

Visualizing feature embedding
t-SNE : C3D features are projected to 2-dimensional space

Action Similarity Labeling
action similarity labeling : 두 개의 영상이 같은 동작인지 아닌 지 구별하는 것 ( 본 적 없는 영상으로 구성되어 있기 때문에 어려움 )
각 비디오에서 48차원 벡터 생성 => 정규화
linear SVM이 48차원 벡터에 대해 같은 영상인지 다른 영상인지 분류
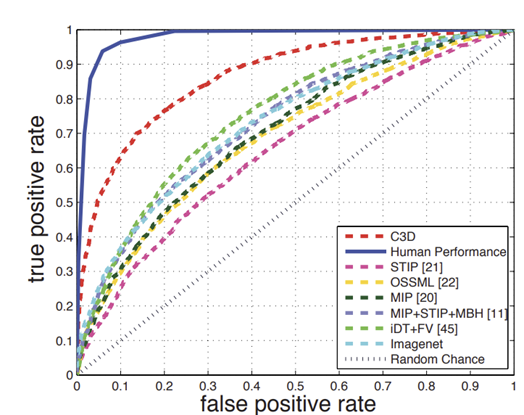
Scene and Object Recognition
Scene and Object Recognition : clip에서 가장 많이 발생하는 label을 ground truth label (8 frame 이아 발생 시 no object) 이라 하고 이를 찾아내는 task
C3D is trained only on Sports-1M while Imagenet is fully trained on 1000 object categories => C3D is generic
'paper review' 카테고리의 다른 글
| You Only Look Once: Unified, Real-Time Object Detection (CVPR, 2016) (0) | 2023.08.06 |
|---|---|
| Fatigue Detection on Face Image Using FaceNet Algorithm and K-Nearest Neighbor Classifier (0) | 2023.06.29 |

